Databricks
統合型データ&AIプラットフォーム
企業や組織が膨大かつ多様なデータを、安全・高速・柔軟に活用するためのプラットフォームです。
SUMMARY Databricksとは
Databricks(データブリックス)は、企業や組織が膨大かつ多様なデータを、安全・高速・柔軟に活用するための統合型データ&AIプラットフォームです。
もともとは、ビッグデータ処理エンジン「Apache Spark」の開発メンバーである研究者たちが、米・カリフォルニア大学バークレー校のAMPLabでの研究成果を基に設立しました。現在では、Amazon Web
Services、Microsoft Azure、Google Cloud
Platformといった主要クラウドに対応し、世界109カ国、10,000社以上の企業で利用されている信頼性の高いソリューションです。
近年、企業活動において「データ活用」は避けて通れないテーマとなっており、DX(デジタルトランスフォーメーション)を成功させる上でも中核的な要素となっています。しかし、実際には「データが各部門で分断されている」「データ量が多すぎて処理できない」「AIを使いたいが人材も仕組みもない」といった課題を抱える企業も少なくありません。
Databricksは、そうした課題に対し、データの収集・変換・分析・AI活用までをワンプラットフォームで支援することで、企業のDX推進を加速し、データから真のビジネス価値を引き出す環境を提供します。
FEATURE Databricksの3つの強み
-
統合型データ
&
AIプラットフォーム

Databricksは、DWHとデータレイクのメリットを併せ持ち、構造化・非構造化データを一元管理できる「レイクハウス」を採用し、データの収集・変換・分析・AI活用までを一貫して行える統合環境を提供します。
機械学習のライフサイクルを管理するMLflowや、大規模言語モデル(LLM)構築を支援するDBRXなど、AI領域にも強く、データエンジニア・データアナリスト・データサイエンティストが協業しやすい設計になっています。
リアルタイム処理、バッチ処理、ストリーミング、BI分析など、あらゆるユースケースに柔軟に対応可能です。 -
従量課金&低コスト


Databricksは、ストレージと仮想マシンを分離したアーキテクチャにより、必要なときだけ仮想マシンを起動し、処理後は自動停止することで無駄なコストを削減できます。
利用量に応じたDBU(Databricks Unit)による従量課金制に加え、長期契約や予約インスタンスによる価格最適化にも対応しています。
このような仕組みにより、実際にTCO(総所有コスト)の大幅な削減を実現している企業も多数存在し、Databricksへの移行によって数十%単位でのコストダウンを報告している事例もあります。 -
グローバルでの
高い導入実績

Databricksは現在、世界109カ国、10,000社以上の企業に導入されており、その中にはFortune 500企業の60%以上が含まれます。
Shell、HSBC、Unilever、Microsoft、Comcast、Atlassianなど、業界をリードする企業がデータ基盤やAI活用の中核としてDatabricksを選択しています。
また、AI領域における急成長企業としても注目されており、グローバルな実績と信頼性の高さは、導入検討時の安心材料となり、社内の意思決定にも大きな後押しとなります。
ABOUT ABY3
エーバイスリー
セキュアシステムとは
エーバイスリーセキュアシステム株式会社(ABY3 Secure
System)は、『Automation(自動化)・Analysis(分析)・AI(人工知能)』の3つの領域をコアコンセプトとする、次世代型のセキュリティ&データソリューション企業です。社名の「A×3」には、これらの先端技術を融合し、お客様の課題解決に本質的に寄与するという想いが込められています。
創業以来、私たちはビッグデータ活用の最前線で、Splunkをはじめとする高度なプラットフォームを用いたデータ分析・可視化・異常検知のプロジェクトを多数支援してきました。単なるシステム導入にとどまらず、要件定義から設計・構築、さらには運用保守フェーズに至るまで一貫したサポート体制を提供しています。
特に運用・保守領域では、御社専任のエンジニアをチームとしてご提案・配置し、現場に寄り添いながら改善と進化を継続支援するスタイルを大切にしています。
このように、『納品で終わらない、成果が出るまで伴走する』という姿勢が、多くのお客様から信頼を得ています。
私たちは、お客様のDX(デジタルトランスフォーメーション)を構想から実装・運用まで一緒に走り切るパートナーとして、これからも技術と現場力の両面から貢献してまいります。
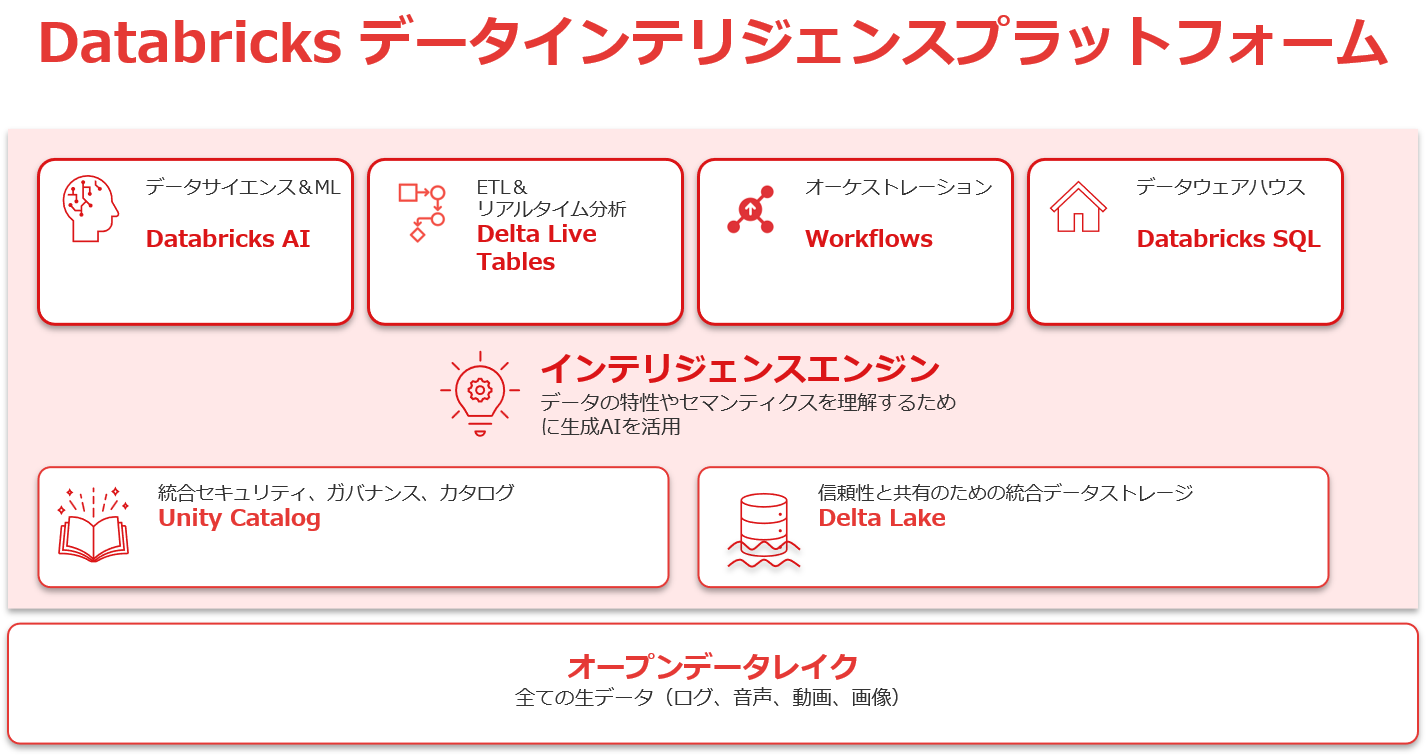
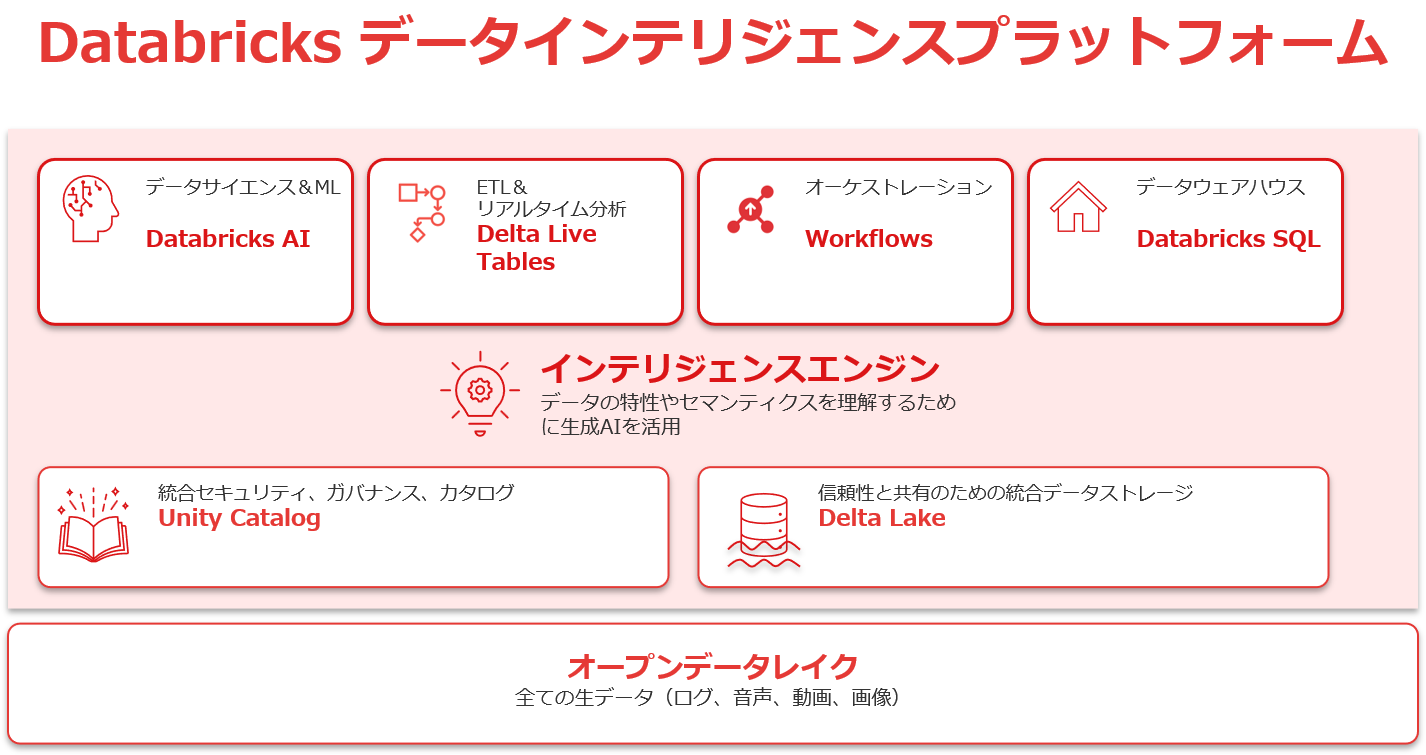
FUNCTION Databricksの機能
-
Delta Lake
大規模データ処理における信頼性と一貫性を実現する、Databricksの中核ストレージ技術。ACIDトランザクション対応により、分散環境でも整合性の取れた書き込みや更新が可能。スキーマ管理やタイムトラベル、アップサート(MERGE)などの機能を備え、バッチ処理からストリーミング分析まで幅広く対応します。信頼性の高いデータ基盤の構築に不可欠です。
-
Unity Catalog
Databricksにおける統合データガバナンス機能。データ・モデル・ノートブック・ダッシュボードなど、あらゆる資産に対してアクセス制御、分類、監査記録を一元管理可能。ロールベースのセキュリティ設定やタグ付けにも対応し、複数ワークスペース間の統合管理も実現。コンプライアンスやセキュリティ要件が厳しい組織に最適です。
-
Databricks SQL
構造化データに対して、BI用途で使いやすい高速なSQLクエリエンジンと可視化機能を提供。データ分析者や業務部門がノーコードに近い形でデータを活用でき、ダッシュボードの作成や共有も簡単に行えます。スケジューリングやアラート機能も備え、Power BI や Tableau など既存のBIツールとの連携にも優れています。
さらに、DatabricksではSQL以外にも、Spark SQL(分散処理基盤上で動作するSQLエンジン)や、PySpark(Pythonによる分散データ処理)、Pandas(軽量データ分析)、Scala、Rといった複数の言語に対応しており、ユーザーのスキルや用途に応じて柔軟に選択可能です。これにより、ビジネスアナリストからデータエンジニア、サイエンティストまで、同じプラットフォーム上で効率的に協業できる点が大きな強みです。 -
Notebook
Databricks上で複数言語(Python、SQL、Rなど)を統合的に扱えるインタラクティブな開発環境。コード、グラフ、コメントをひとつの画面で共有・記述でき、分析や機械学習、データ処理の効率を大幅に向上。コラボレーション機能も豊富で、Git連携やバージョン管理も可能。技術者間の共同作業やナレッジ共有にも強みを発揮します。
-
Workflow
ETL処理や機械学習ジョブを定期実行・自動化するためのジョブオーケストレーション機能。依存関係やスケジュール設定、エラーハンドリングにも対応し、再現性と信頼性のあるデータパイプライン構築が可能です。GUIベースでの設定や通知機能、ジョブの再試行設定なども備えており、運用の負荷を大きく軽減します。
-
Delta Live Tables
ETL処理をSQLまたはPythonで宣言的に記述するだけで、自動的にデータパイプラインを生成・管理できる機能。スキーマ変更への自動対応や、データの検証・監視・エラー通知などの運用機能を内蔵しており、信頼性の高いリアルタイム処理やストリーミング分析が容易に実現できます。データ品質と保守性を重視するプロジェクトに最適です。
-
MLflow
機械学習の実験管理、パラメータやメトリクスの記録、モデルの登録・デプロイを一元化するオープンソースのMLライフサイクル管理ツール。Databricksに統合されており、再現性のある開発や本番運用におけるバージョン管理が容易。Web UIやAPIを通じてモデルの比較や再利用が可能で、チーム間の連携やMLOps推進にも貢献します。
-
Vector Search
テキストや画像などの非構造データをベクトル化し、意味的な類似性に基づいて検索できる機能。生成AIと組み合わせることで、ドキュメント検索、FAQシステム、チャットボットなどに高精度な回答を提供可能。Databricks上で統合的に構築・管理でき、セキュアな環境でRAG(検索拡張生成)アプリの開発が行えます。
-
Databricks GenAI Studio
生成AIアプリをGUIベースで開発できる統合環境。プロンプト設計、RAG構成、外部LLMの呼び出し(OpenAI、Anthropic、Metaなど)までをノーコードで構築可能。社内文書や業務データを活用したAIチャットや自動要約アプリなども短期間で実装でき、生成AIの業務利用を本格的に推進したい企業にとって理想的な開発基盤です。
-
Databricks Assistant
Notebook上で動作する生成AIアシスタント。自然言語によるSQL生成、Pythonコードの補完、エラー内容の説明、最適化提案などに対応。初学者の支援から、上級者の生産性向上まで幅広く活用でき、開発・分析作業の効率化を強力にサポートします。チームの技術格差を埋めるツールとしても有効です。
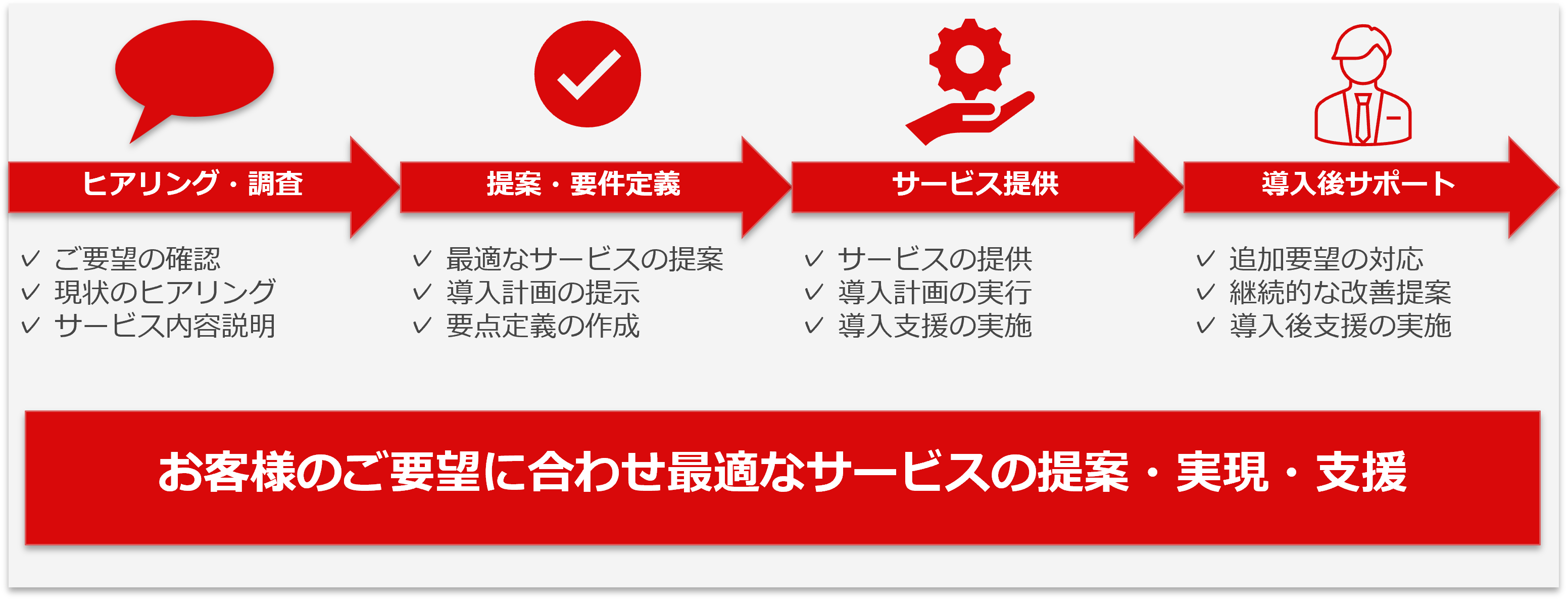
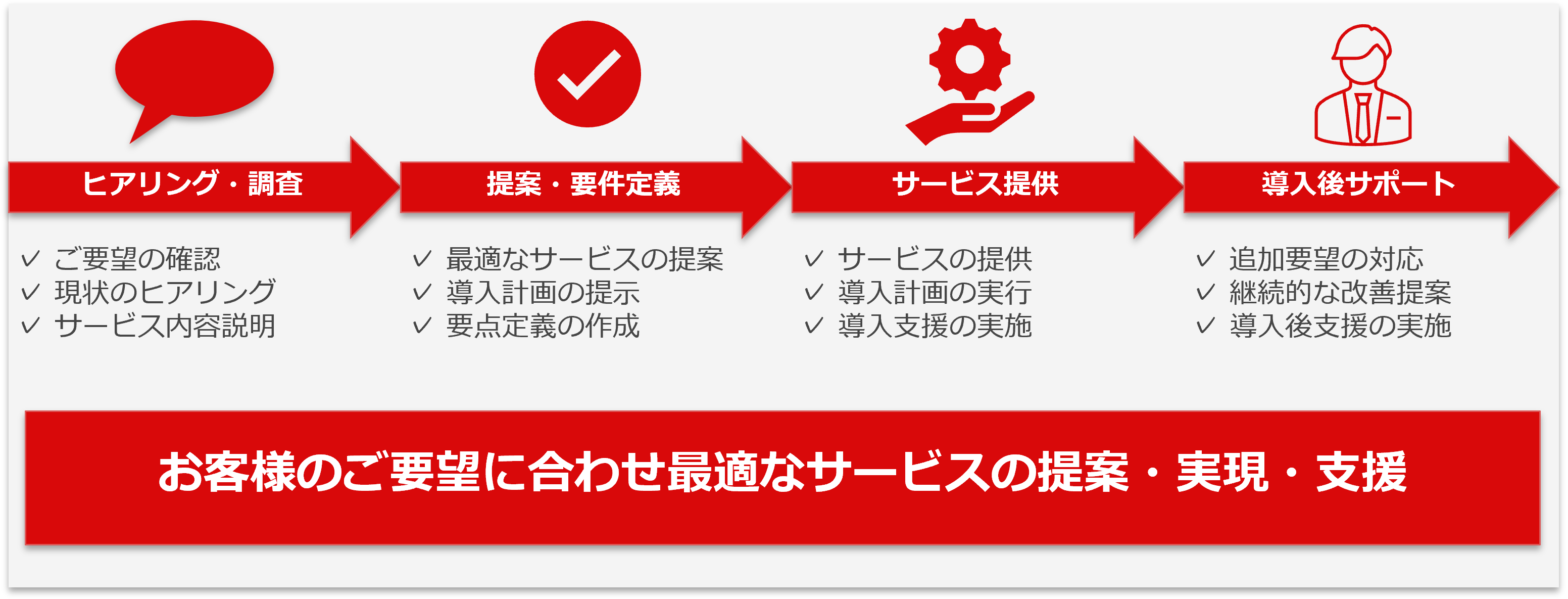
INTRODUCTION FLOW
Databricks
導入の流れ
弊社が提供する導入支援では、お客様の課題や目的を丁寧にヒアリングし、最適な導入プランをご提案します。 要件定義では既存システムやデータ構成を踏まえ、効率的かつセキュアな分析基盤を設計します。 構築フェーズでは、環境のセットアップからデータ連携、アクセス制御までを包括的に実施します。 導入後も継続的な運用支援やパフォーマンス改善提案を行い、ビジネスに最適化されたデータ活用環境を維持します。 初期検討から運用フェーズまで、ワンストップでお客様のデータ活用を支援します。